symbolic derivatives and the rust rewrite of RE#
a few weeks ago i wrote about how we built the fastest regex engine in F#. that post ended up getting surprisingly big on hacker news, which was both exciting and a little terrifying - nothing like mass attention on your work to find all the things you forgot to mention. also learned that a lot of people have strong feelings about casual lowercase writing, on my own blog. but it also confirmed something i'd been hoping: people are genuinely interested in extended regex operators, and there's real demand for an algorithm that can support them efficiently.
luckily, regex is good at more than you'd think - here's one that fixes the capitalization for you. it even uses lookarounds to avoid capitalizing the middle of words - something we'll also mention in this post:
so here's the update: RE# now has a rust implementation which is open source as well. the core engine is available as a crate on crates.io, and it's what this post is about.
why rewrite it
RE# was always meant to be a standalone native library without dependencies, so we could use it from any language and platform, and a recurring theme in the HN comments was "cool, but i'm not pulling in .NET for a regex engine". fair enough - the F# implementation leaned heavily on .NET's infrastructure, and that ties you to a runtime. rust fixes that.
the rust version has actually been in the works for a while as an experimental rewrite. rather than porting the F# code, we built on a different foundation, using fully symbolic derivatives rather than the minterm-compressed Brzozowski derivatives that the dotnet version uses. the core ideas are the same (minterms, lazy DFA, bidirectional matching), but the algebraic foundation underneath is different enough that i'd call it a separate engine that happens to accept the same syntax.
it also supports more patterns. the dotnet version restricts lookarounds to the normalized form (?<=R1)R2(?=R3) where R1/R2/R3 can't contain lookarounds. the rust version lifts that restriction on lookaheads entirely, so you can use them freely. not a big enough increment for a publication of its own, but a meaningful improvement for real-world use.
performance
as mentioned in the previous post, the F# version gets a lot of its speed from .NET's SIMD infrastructure - SearchValues<T>, Teddy multi-string search, right-to-left vectorized scanning. the rust version doesn't have any of that yet, so literal-heavy patterns aren't where it shines. but where the DFA loop dominates and there's less reliance on vectorized prefilters, it holds up well:
| benchmark | resharp | regex crate | fancy-regex | vs regex crate |
|---|---|---|---|---|
| dictionary, ~2678 matches | 424 MiB/s | 57 MiB/s | 20 MiB/s | 7.4x faster |
dictionary (?i) | 505 MiB/s | 0.03 MiB/s | 0.03 MiB/s | 16,833x faster |
lookaround (?<=\s)[A-Z][a-z]+(?=\s) | 265 MiB/s | -- | 25 MiB/s | -- |
| literal alternation | 490 MiB/s | 11.3 GiB/s | 10.0 GiB/s | 23x slower |
literal "Sherlock Holmes" | 13.8 GiB/s | 39.0 GiB/s | 32.7 GiB/s | 2.8x slower |
the last two rows are where we lose, and it's not close - regex uses Teddy/SIMD for literals and short alternations, and we simply don't have that yet. the "Sherlock Holmes" gap is partly because our skip loop searches for a lowercase s (the start byte of the DFA state) while regex searches for an uppercase S which is much rarer in english text - a simple statistical difference but nothing we can't fix. the case-insensitive row goes the other way: regex falls back to an NFA when case-insensitivity with (?i) blows up the state space, dropping to 0.03 MiB/s. yes, that 16,833x number is real - this is exactly the NFA slowdown i described in the previous post. it's not a pathological input, just case-insensitive matching on a dictionary. O(n * m) is technically linear in n, but when m blows up it stops feeling linear real fast.
update: since publishing this post, both literal performance gaps above have closed - the literal alternation and "Sherlock Holmes" cases are now within noise threshold of the regex crate.
what actually changed in the rewrite
this is the fifth reimplementation of the same ideas, and each one fixes some mistakes of the last. the first released version (SBRE) is from 3 years ago and a lot has changed since then.
the biggest difference is in the derivative algorithm itself. the F# version uses compressed Brzozowski derivatives - the rust version uses symbolic derivatives and transition regexes, a symbolic generalization of Brzozowski derivatives, which changes how the algebra works internally. another major change is encoding: the F# version works on UTF-16 chars because that's what .NET gives you, while the rust version works on raw bytes with UTF-8 awareness.
the parser is also completely different. instead of extending .NET's regex parser, we build on top of the regex-syntax crate. it already handles the full standard syntax, unicode properties, and all the edge cases that took years to get right. on top of that, we add three extensions: & for intersection, ~(...) for complement, and _ for the universal wildcard - same syntax as the dotnet version.
i also added a \p{utf8} class that lets you constrain matches to valid UTF-8. rust's regex crate guarantees that matches only occur on valid UTF-8 boundaries, so how do you do that when your engine operates on raw bytes? you intersect (&) with the language of valid UTF-8 sequences:
// \p{utf8} expands to:
// ([\x00-\x7F]
// | [\xC0-\xDF][\x80-\xBF]
// | [\xE0-\xEF][\x80-\xBF]{2}
// | [\xF0-\xF7][\x80-\xBF]{3})*so if you write \p{utf8}&~(a), you get "anything except a, but only valid UTF-8". it's just another constraint you compose into the pattern.
use resharp::Regex;
// basic matching
let re = Regex::new(r"hello.*world").unwrap();
assert!(re.is_match("hello beautiful world"));
// intersection: contains both "cat" and "dog", 5-15 chars
let re = Regex::new(r"_*cat_*&_*dog_*&_{5,15}").unwrap();
// complement: does not contain "1"
let re = Regex::new(r"~(_*1_*)").unwrap();i ran some comparisons on state representation width - 16-bit state IDs fit noticeably better into CPU cache than wider ones, and if you're hitting 64K+ states you're probably better off splitting into two simpler patterns anyway. one design decision i'm happy with is that when the engine hits a limit - state capacity, lookahead context distance - it returns an error instead of silently falling back to a slower algorithm. as the benchmarks above show, "falling back" can mean a 1000x+ slowdown, and i'd rather you know about it than discover it in production. RE# will either give you fast matching or tell you it can't.
fully symbolic derivatives & transition regexes
in the previous post i described Brzozowski derivatives: you take a regex and a character, and get back a new regex that matches whatever is left after consuming that character. der(hello, h) = ello. simple, elegant, and the foundation of everything RE# does.
but there's a problem with the classical formulation. the derivative takes a regex and a character, so to build a state machine you need to compute it for every possible character to get all transitions from a given state. sure, you can compress the number of characters into equivalence classes before, but you still have to compute for each equivalence class - and many of them end up leading to the same state anyway. for example, the regex abc (below) cares about a, b, c, and "everything else", which brings us down from 65536 to 4 in UTF-16, but for the first node (abc) even b and c behave the same as "everything else". so what are we computing these for? in other words, there is something left to improve here.
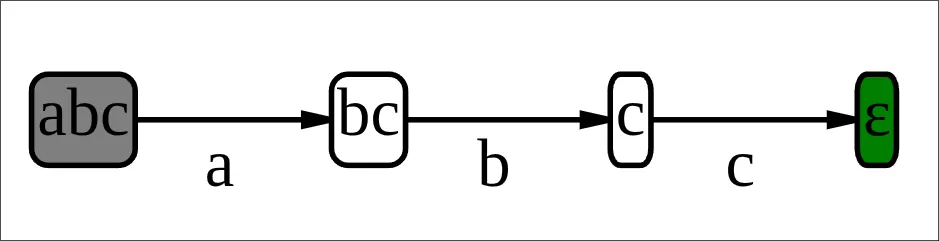
symbolic derivatives flip this around. this concept comes from my advisor Margus Veanes - for a more formal definition, see the LPAR paper on symbolic derivatives and transition regexes. the idea is that instead of asking "what happens when i read character X?", you ask "what happens when i read any character?" and get back a decision tree that covers all possibilities at once - an if-then-else tree:
enum TRegex {
Leaf(NodeId),
ITE(CharSet, TRegexId, TRegexId),
}ITE stands for if-then-else. ITE([a-z], leaf(R1), leaf(R2)) means: "if the character is in [a-z], the derivative is R1, otherwise it's R2". these trees can nest, splitting the character space into finer partitions as needed. the key insight is that the derivative function never takes a character argument - it produces a complete map from all possible characters to their resulting states in one shot.
this also means minterms come for free. the ITE tree is already a partition of the character space into equivalence classes - you just read them off. there is no separate minterm-extraction pass.
the derivative rules are structurally the same as Brzozowski's:
der(R1 & R2)= combineder(R1)andder(R2)with intersectionder(~R)= complement ofder(R)der(R1 · R2)=der(R1) · R2, plusder(R2)ifR1is nullableder([a-z])=ITE([a-z], ε, ⊥)- the base case, where a character set predicate produces the simplest possible decision tree
the difference is that every operation works on decision trees instead of individual nodes, and the combining operations (union, intersection, complement) know how to merge two trees by splitting on shared conditions. the result is that you compute one derivative per state instead of let's say, 256 for a byte, and the minterms fall out for free.
of course this rabbit hole goes deeper, and we have a paper using this technique for string constraint solving that i'd love to derail this post into, but i'll save that for another time. the main point is that symbolic derivatives are a more powerful and efficient generalization of Brzozowski's original idea, and they form the core of the new RE# engine. fun fact: symbolic derivatives are also implemented in Z3 (the SMT solver) for its sequence theory - so in some sense we're inching closer to having an SMT solver's core internals inside a regex engine.
unrestricted lookaheads
both the dotnet and rust versions of RE# match all lookaheads in a single pass - this isn't new to the rewrite. this is easier to show than describe - hit play to see stacked lookaheads in a traditional engine vs RE#:
(?=.*a)(?=.*b)(?=.*c)def against "defxaxbxcx"RE# does it all in a single pass with no rewinding. the key idea is that instead of treating (?=L) as a standalone zero-width assertion followed by the rest of the pattern R, the engine fuses them into a single node: lookahead(body=L, tail=R). the body is what the lookahead needs to verify, and the tail is whatever comes after it. both get derived together as the engine advances through the input. here's what that looks like for stacked lookaheads:
// (?=A)(?=B)C
standard: (?=A) · (?=B) · C
resharp: lookahead(body=A, tail=lookahead(body=B, tail=C))this nesting also opens the door to a nice optimization: when consecutive lookaheads all check the same stretch of input, the engine can flatten their bodies into a single intersection. it's still a single pass either way, but flattening is cheaper on the algebra side. here's a concrete example - a password-style pattern that requires an uppercase letter, a digit, and a special character:
// (?=.*[A-Z])(?=.*[0-9])(?=.*[!@#]).*
// step 1: wrap first lookahead
lookahead(body=.*[A-Z].*, tail=(?=.*[0-9])(?=.*[!@#]).*)
// step 2: flatten - second lookahead body merges in
lookahead(body=.*[A-Z].* & .*[0-9].*, tail=(?=.*[!@#]).*)
// step 3: flatten again - all three bodies intersected
lookahead(body=.*[A-Z].* & .*[0-9].* & .*[!@#].*, tail=.*)
(.*[A-Z].* & .*[0-9].* & .*[!@#].*)what's new in the rust version is that these syntactic forms are now supported. (?=.*a)(?=.*b)(?=.*c)def is semantically equivalent to def(?=.*a)(?=.*b)(?=.*c) since the lookahead bodies are unrelated to def, but the first form doesn't fit the (?<=R1)R2(?=R3) lookaround normal form that the dotnet version requires, so its parser rejects it. same goes for lookaheads inside union branches - something like (a(?=x)|b(?=y)|c(?=z)) where each alternative has its own lookahead condition is perfectly valid but doesn't normalize into a single R2(?=R3). the rust version handles all of these.
the core derivative rule is simple. for lookahead(body, tail):
- if
bodyis nullable: the assertion is satisfied, returnder(tail) - otherwise: derive both parts and reassemble -
lookahead(der(body), der(tail))
that's it. the body and tail advance together through each character, and when the body finally becomes nullable the lookahead dissolves and only the tail remains. the actual implementation is slightly more involved, but the idea is all here.
now that i've written it out, it seems obvious - of course you can treat the lookahead as a single unit and derive it together. but it took a while to get there with all the edge cases and weird interactions between the context tracking and the derivative construction.
character sets as 256-bit vectors
one nice thing about working with bytes instead of UTF-16 is that a character set - the predicate in each ITE node - can be represented as a 256-bit bitvector. one bit per possible byte value. in the rust version this is just four u64s packed into a struct:
struct TSet(pub [u64; 4]);all the boolean operations on character sets become bitwise operations: intersection is AND, union is OR, complement is NOT. checking if a byte belongs to a set is a single bit test. checking if two sets are disjoint is AND followed by comparing to zero. these are all constant-time operations, and on AVX2 each one is a single instruction over the full 256 bits.
the dotnet version uses BDDs (binary decision diagrams) for the same purpose, which is the right call for UTF-16 where you have 65536 possible values. but for bytes, a flat bitvector is simpler, faster, and fits in four registers. no tree traversal, no cache misses, no allocations. the Solver type in resharp-algebra is basically a deduplicated store of these bitvectors - each unique character set gets a TSetId, and all operations go through the solver to maintain sharing.
skip acceleration
one optimization that i didn't mention in the previous post but exists in both versions is skip acceleration. almost all serious regex engines have some form of this - the idea is simple: many states will self-loop on the majority of input bytes. for example, .* loops back to itself on every byte except \n - so why run the DFA transition 999 times when you can look up a whole chunk of the input in parallel and jump directly to the next \n? going back to the matching loop pseudocode from the previous post:
state = 0
for character in input:
+ if skipBytes[state]: character = vectorized_search(skipBytes[state], input)
charKind = charClassTable[character]
state = nextStateTable[state, charKind]
if matchTable[state]: print "confirmed: a match happened"this is how literal-prefix patterns hit 10+ GiB/s - the engine skips over most of the input with SIMD-accelerated byte search and only runs the DFA when something interesting shows up.
the engine detects these opportunities automatically during construction by checking (now symbolically) which bytes cause a state to transition elsewhere vs loop back to itself.
what's next
there's still work to do. the biggest gaps are SIMD prefilters for non-literal patterns - the dotnet version gets a lot of mileage from vectorized character class membership tests that we don't have yet - and the bidirectional SIMD routines needed for our right-to-left scanning. there's also other low-hanging fruit - we don't have any statistical optimizations yet, the Unicode classes could be baked in instead of constructing them while parsing, the memory usage could be improved, there are many pattern-specific shortcuts we could add, and so on. but i hope the benchmarks show that it's already competitive and useful in its current state.
the code is on github and available on crates.io. try it out, break it, and let me know what you find.