RE#: how we built the world's fastest regex engine in F#
around a year ago, we built a regex engine in F# that not only outperformed the ones in dotnet, but went above and beyond competing with every other industrial regex engine on a large set of industry-standard benchmarks. it also supports the full set of boolean operators (union, intersection, complement) and even a form of context-aware lookarounds, which no other engine has while preserving O(n) search-time complexity. the paper was published at POPL 2025, and i figured it's time to open source the engine and share the story behind it. consider it a much more casual and chatty version of the paper, with more focus on engineering aspects that went into it.
#r "nuget: resharp"
// find all matches
Resharp.Regex("hello.*world")
.Matches("hello world!")
// intersection: contains "cat" AND "dog" AND is 5-15 chars long
Resharp.Regex(
"_*cat_*&_*dog_*&_{5,15}")
.Matches(input)
// complement: does not contain "1"
Resharp.Regex("~(_*1_*)")
.Matches(input)brief introduction
almost every regex engine today descends from one of two approaches: Thompson's NFA construction (1968) or backtracking (1994). Thompson-style engines (grep, RE2, Rust's regex) give you linear-time guarantees but only support the "standard" fragment - | and *. backtracking engines (the rest, 95% chance the one you're using) give you a mix of advanced features like backreferences, lookarounds.., but are unreliable, and can blow up to exponential time on adversarial inputs, which is a real security concern known as ReDoS. to be more precise, this exponential behavior is not the only problem with backtracking engines - they also handle the OR (|) operator much slower, but let's try to start with the big picture.
neither camp supports intersection (&) or complement (~), which is a shame because it's been known as early as 1964, but forgotten since then, before being brought to attention again in 2009, or as Owens, Reppy and Turon put it, it was "lost in the sands of time".. and forgotten again until redgrep (2014) and later 2019, when it saw industrial use for credential scanning in SRM, albeit these operators were not exposed to the user back then. RE# is inspired by existing implementations of SRM and .NET NonBacktracking engine (2023), but in a way that hadn't been done before, and with a lot of engineering work to make it fast and practical for real-world use cases.
a big goal of our paper was to really highlight how useful these operators really are. making it fast was more of a side-goal, so there would be less to complain about, as there was already a lot of disbelief, and we got comments such as it being a "theoretical curiosity". i spent over a year experimenting with different approaches (there's an initial draft on arXiv from 2023 where lookarounds had much worse complexity), but finally we found a combination that works extremely well in practice, and it helped me find a deeper intuition for what works both in theory and in the real world.
the result is RE#, the first general-purpose regex engine to support intersection, complement and lookarounds with linear-time guaranteeshonorable mentions: Paul Wankadia's redgrep has had intersection and complement with linear-time matching and derivatives for over a decade. also SBRE and LTRE which support both as well. RE# adds a leftmost-longest non-overlapping matches algorithm and lookarounds on top & and ~., and also the overall fastest regex engine on a large set of benchmarks. we also wanted to address some more things along the way, like returning the correct matches (the ones you meant, leftmost-longest), when the default semantics are given by the PCRE implementation. or put another way, "it's correct if it does whatever the one that blows up and causes denial of service does".
Brzozowski derivatives
a core building block of RE# is the concept of regex derivatives, which is equally old, and equally forgotten until 2009 when it was rediscovered and 10 years later implemented in .NET for credential scanning.
both derivatives and intersection/complement operators originally came from a 1964 paper by Janusz Brzozowski (below).
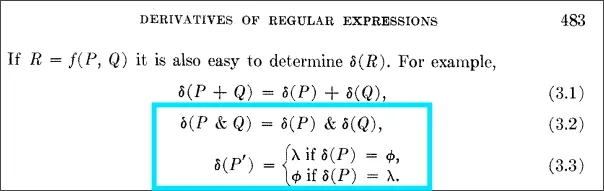
don't let the complex notation scare you - the core idea is extremely simple. the derivative of a regex R and a character c is simply whatever is left to match after removing the first character.
- derivative of
helloandhisello - derivative of
abcandxis∅(intuitively, the match failed here) - derivative of
cat|dogandcisder(cat,c) | der(dog,c), which isat|∅and simplifies toat
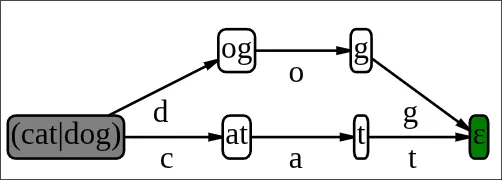
you can match a string by repeatedly taking derivatives for each character. when you've consumed the entire input, you check if the resulting regex accepts the empty string (is "nullable"). if yes, the original string matched.
what makes this elegant is that derivatives naturally extend to intersection and complement:
- derivative of
.*a.*&.*b.*withais.*b.* - derivative of
~(abc)withais~(bc)
it just works. the boolean operators distribute over derivatives the same way union does. derivatives are such a powerful and interesting tool that i will dedicate a separate post to them, but the main point is that they give us a simple and uniform way to handle all regular language features, including intersection and complement.
Ken Thompson, perhaps one of the most well-known computer scientists of all time, created the grandfather of all regex algorithms in 1968, inspired by Brzozowski's work, but only included OR (|) as a boolean operator. and somewhere in the process also changed the meaning of union to alternation by always choosing the left branch when both branches could match, but let's skip ahead, we got plenty more tangents to avoid here.
the point i want to get to with Thompson's paper is that the last few sentences of Thompson's original paper actually mention the possibility of intersection and complement (below), but the funny thing is that this footnote has been forgotten for decades, and no one ever followed through.. and for the ones who tried, in fact, it wasn't so easy in Thompson's NFA framework at all, the devil is in the details.

separation of concerns
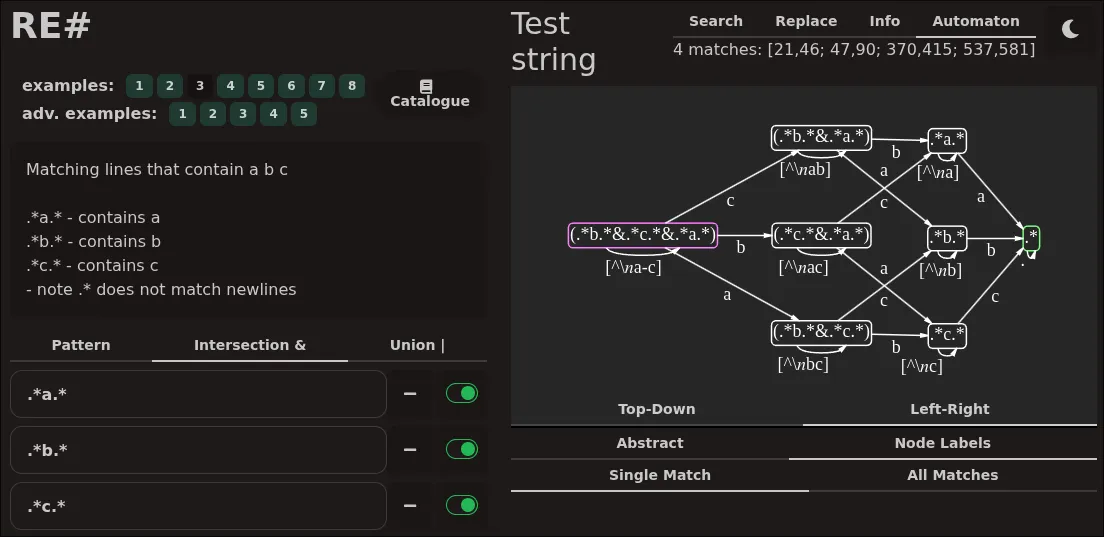
the biggest gain from & and ~ is that they let you mix and match regexes. instead of writing a single spaghetti monster regex that tries to do everything, you can break it down into smaller, simpler pieces and then combine them with boolean operators. this makes your regexes easier to read, write and maintain. this is best illustrated in the web app that came with the paper (https://ieviev.github.io/resharp-webapp/) where you can visually see how the different components of a regex are combined, and how they contribute to the final match.
as we wrote in the paper, RE# lets you write small fragments of regexes that describe individual properties of the matches you want, and then combine them with boolean operators to get the final result (below).
- `_*` = any string
- `a_*` = any string that starts with 'a'
- `_*a` = any string that ends with 'a'
- `_*a_*` = any string that contains 'a'
- `~(_*a_*)` = any string that does NOT contain 'a'
- `(_*a_*)&~(_*b_*)` = any string that contains 'a' AND does not contain 'b'
- `(?<=b)_*&_*(?=a)` = any string that is preceded by 'b' AND followed by 'a'
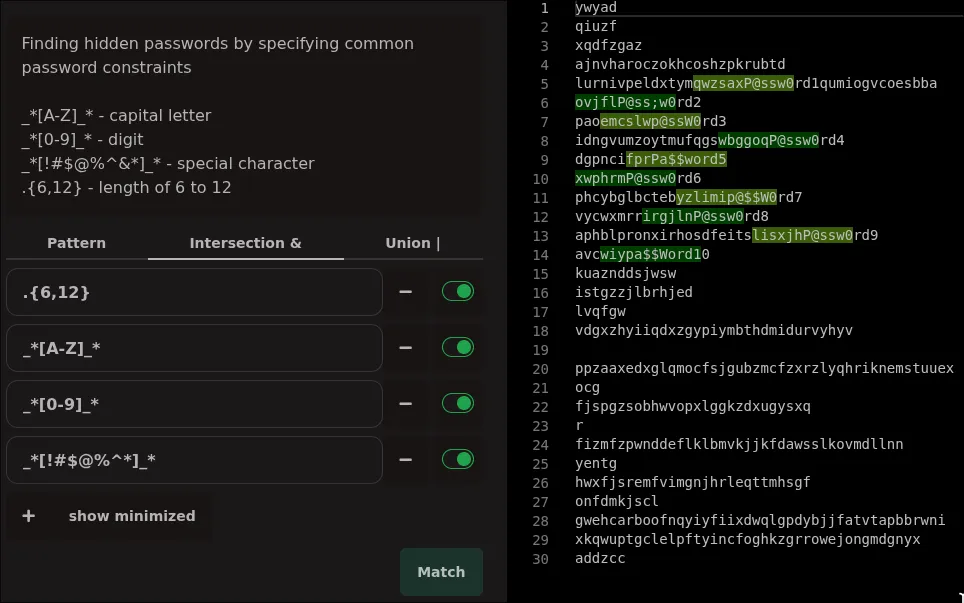
- .. you combine all of these with `&` to get more complex patternsand as a result of this specification, you will get a fast, reliably correct algorithm that finds them. for example, if you have a notebook full of passwords, which you want to strip out before sharing, you can write a few fragments of a regex that each describe a property of passwords (e.g., contains at least 8 characters .{8,}, at least one uppercase letter _*[A-Z]_*, at least one digit _*[0-9]_*, and at least one special symbol _*[!#$@%^*]_*). and you can toggle each one on and off to see how it affects the matches. this is a nice intuitive way to write regexes, since intersection preserves the meaning of the original patterns and simply combines them, it works exactly as you would expect!
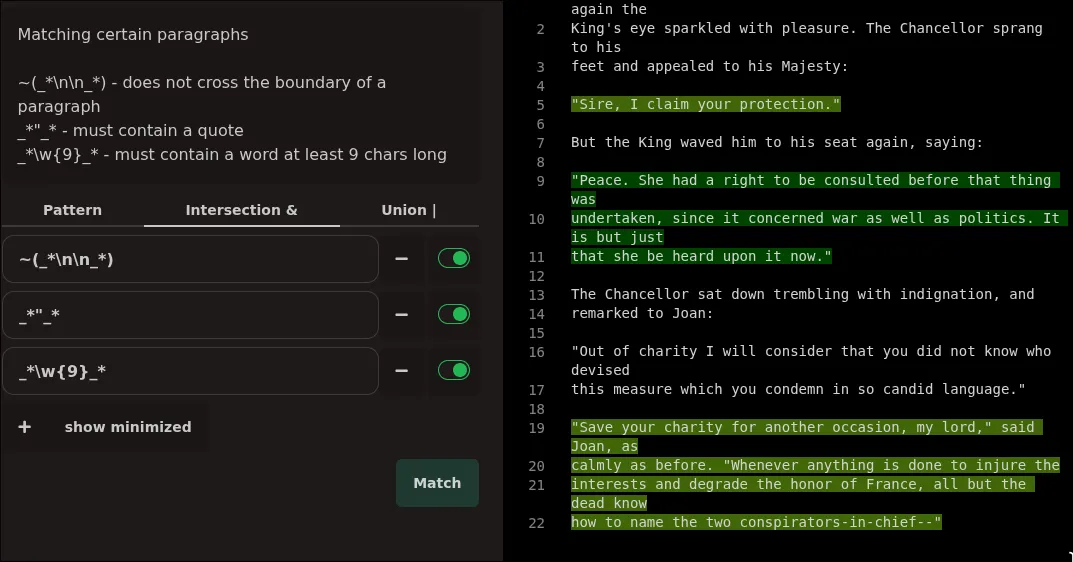
another good example is searching through paragraphs (below), which contain some combination of keywords. here the important part is ~(_*\n\n_*), or "does not contain two consecutive newlines", in other words, the boundary of a paragraph, so it matches paragraphs! then you can combine it with any other regex to find paragraphs that contain certain keywords, but not others. this is very hard to do with traditional regexes without writing a complex and fragile pattern that tries to match the entire paragraph structure.
neat, right? and this is just the tip of the iceberg. there are so many more use cases where these operators shine, and i encourage you to play around with them in the web app and see what you can come up with. you can also see the resulting automaton for each regex, and how the different components contribute to the state machine (msagl helped me a lot here).
minterms: compressing the alphabet
a naive implementation of derivatives would need to compute a transition for every possible character (up to 65536 in UTF-16). minterms fix this by partitioning the character space into equivalence classes where all characters in a class behave identically.
for example, the regex [a-zA-Z] only cares about two kinds of characters: letters and everything else. so instead of individually taking derivatives for 52 alphabet characters a..z, A..Z, we can conclude from the start that there are only two kinds of characters we care about: letters ([a-zA-Z]) and non-letters ([^a-zA-Z]).
we assign a minterm id to each of these classes (e.g., 1 for letters, 0 for non-letters), and then compute derivatives based on these ids instead of characters. this is a huge win for performance and results in an absolutely enormous compression of memory, especially with large character classes like \w for word-characters in unicode, which would otherwise require tens of thousands of transitions alone (there's a LOT of dotted umlauted squiggly characters in unicode). we show this in numbers as well, on the word counting \b\w{12,}\b benchmark, RE# is over 7x faster than the second-best engine thanks to minterm compressionremark here i'd like to correct, the second place already uses minterm compression, the rest are far behind. the reason we're 7x faster than the second place is in the \b lookarounds :^).
DFA matching loop
the core DFA algorithm is also very simple. now i know, coming from someone who's been doing years of PhD research on this topic, but it really is simple. you got 4 things:
- a state you're currently in (state 1, state 2, etc.)
- an input character (or a stream of characters)
- a big lookup table that tells you if state is 1 and character is 'a', go to state 5
- another big lookup table that tells you if you're in state 5 you got a match
and the pure algorithm pseudocode is just:
state = 0
for character in input:
state = nextStateTable[state, character]
if matchTable[state]: print "it was in there"add the minterm compression on top of this, that's one extra (5th) detail:
- lookup table that tells you characters a-z belong in class 1, and the rest in class 0
state = 0
for character in input:
+ charKind = charClassTable[character]
- state = nextStateTable[state, character]
+ state = nextStateTable[state, charKind]
if matchTable[state]: print "it was in there"and this loop runs very hot, near a trillion operations per second in L1 cache, so you want to avoid any other overhead when possible, compute things ahead of time and so on. but the core algorithm is just this. the rest is engineering and optimizations on top of this.
exiting classical automata territory
now 'it was in there' isn't actually very useful in the real world. you toss the algorithm at 4TB of logs and it tells you "yes it's somewhere in there" - cool, then what. what matters in the real world is where the matches are, and what is around those matches. for that we mark positions during matching, not after. also quite simple to grasp:
state = 0
for character in input:
charKind = charClassTable[character]
state = nextStateTable[state, charKind]
+ if matchTable[state]: print "it happened right here"
- if matchTable[state]: print "it was in there"
if you run this algorithm left to right, it will mark the position of every valid end of a match. if you run it right to left, it will mark the position of every valid start of a match. and if you run it in both directions, you can combine the results to get the leftmost-longest match, which is what you intuitively expect when you think of regex matching. this is a bit more work to set up, but it doesn't change the core algorithm at all.
finite state machines.. deterministic finite automata.. nondeterministic finite automata.. our algorithm is actually none of those things
something that i want to claim is that we don't actually need state machines to be finite at all. in a classical automata world, you would think i am crazy, but we can have an infinite number of states, and it's fast, practical and also guaranteed to terminate. scrap the "finite" and just call it a "deterministic automaton". this pulls the rug out from under the feet of a lot of theoretical work in automata theory, and it's a lot harder to grasp, but it gives us a lot of freedom to do things that are impossible in the classical framework, namely context awareness via lookarounds.
hidden in the idea of derivatives is that the next state isn't merely a number, it's an actual regex, which contains all the information to create the next one. this is a mechanism to encode arbitrary information in the state, and use it to implement lookarounds. the lookarounds that we support are a bit limited compared to backtracking engines, but they are still very powerful and useful in practice, and more importantly, they come with the same performance guarantees as everything else.
lookarounds and context awareness
a very common use case for regexes is to find matches that are preceded or followed by some context. a classical example being all lines that end with 'a'. this requirement is usually expressed with a lookahead, where upon finding an 'a', you look ahead to check if it's the end of the line. in a backtracking engine, this is very easy to implement - you just duct-tape the logic that checks the next character, but in a DFA-based engine, this is impossible because you cannot report "the match is here" if the next character is not even known yet. and by the time you know the next character, the position information is lost, so you can't report the match retroactively (well, unless the distance is fixed of course..).
in RE#, we solve this by encoding the context information in the state itself. below, you can see the state machine for the regex ab(?=cd), which matches an 'ab' only if it's followed by a 'cd'. encoded in the final state, is the information that the match actually happened two characters ago.

looking at our matching loop again, we add another important detail here:
state = 0
for character in input:
charKind = charClassTable[character]
state = nextStateTable[state, charKind]
- if matchTable[state]: print "it happened right here"
+ if matchTable[state]: print "confirmed: a match {rel[state]} characters ago"
RE# supports lookarounds of the form (?<=R1)R2(?=R3), where R1/R2/R3 are regexes without lookarounds. this is a very common pattern in the wild, and it covers a lot of use cases.
it also still supports intersections, as intersections can always be normalized to this form. for example, a(?=R4)&b(?=R5) is internally rewritten as (a&b)(?=R4&R5), which is supported.
this limitation has a purpose - it allows us to have a more efficient matching algorithm implementation, which i don't think is immediately obvious and i don't think there are many experts in the field that fundamentally understand this. before fixing the problem and turning my linear matching algorithm into a quadratic one, make sure you thoroughly understand why we have this limitation.
the reason is that we have only one "kind" of match, and marking the end of the position is always correct. with arbitrary lookarounds, instead of marking the match ended here, you would have to mark the match for lookaround #7 ended here, and the match for lookaround #3 ended 5 characters ago, and the match for lookaround #12 ended 100 characters ago. i had a lot of temptation to support arbitrary lookarounds, and it really does seem like an easy fix at first glance, but the complications arise much later in the match loop, and this is a good example of how some theory just does not hold up when you implement it. as a side note, we can actually loosen this restriction on R3 (above) which is solved in a newer version of RE#, but not R1, because R1 is the one that determines the start position of the match.
automata and complexity
the complexity side of things is harder to explain. you can approach this theoretically, practically, or a mix of both. the theoretical approach is to look at the worst-case time complexity of each algorithm, and the practical approach is to look at how they perform on real-world inputs and benchmarks. let's explore a bit of both.
- Backtracking: everyone in the field knows that backtracking engines (PCRE, java, dotnet, javascript, PHP, ruby, python..) are bad because they are the poster child of denial of service attacks.
O(2^n)match time complexity is not good. most backtracking implementations are a combination of clever optimizations duct taped to a very slow engine - for simple cases it works well, but using a pattern that is not affected by the optimizations, you get to see what the "real" worst-case behavior looks like. - DFA construction is
O(2^m)in the worst case, wheremis the size of the NFA. this is widely known in academic circles, but in practice, most people think well of DFAs because they are used in tools likegrepthat are optimized for the common case. but if you throw a large regex at them, they will blow up in size and become unusable. DFA matching is linearO(n)wherenis the size of the input, and the constant is ~3-4 assembly instructions per character - faster than anything you could write by hand. - NFAs are cheaper to construct, but have a
O(n*m)matching time, wherenis the size of the input andmis the size of the state graph. NFAs are often seen as the reasonable middle ground, but i disagree and will argue that NFAs are worse than the other two. they are theoretically "linear", but in practice they do not perform as well as DFAs (in the average case they are also much slower than backtracking). they spend the complexity in the wrong place - why would i want matching to be slow?! that's where most of the time is spent. the problem is thatmcan be arbitrarily large, and putting a large constant of let's say 1000 on top ofnwill make matching 1000x slower. just not acceptable for real workloads, the benchmarks speak for themselves here. - Lazy DFAs (2010) are a clever optimization to mitigate the
O(2^m)blowup of DFA construction, by only constructing the states that you actually visit. lazy DFAs reduce the theoretical automata construction time to eitherO(2^m)orO(n), whichever is lower. you could argue that it's theoretically no longer linear time, since you could have a regex that creates a new state for every character in the input, but in practice you will keep revisiting the same states. for all intents and purposes it behaves more likeO(n)with some initial wind-up time. the main downside of lazy DFAs is that they are more complex to implement, and you have to ship a compiler as part of your regex algorithm. i want to highlight Rust regex and RE2 as excellent implementations of this approach, which you can also see in the benchmarks.
from this list, the two reasonable options are either DFAs (best choice if you can compile ahead of time) or lazy DFAs (great for both random user input and large regexes). NFAs are just not competitive in reality, and backtracking engines are a security nightmare.
Lazy DFA without NFA construction
for RE# we use an approach similar to the lazy DFA in RE2, but with a twist - we skip the NFA entirely and construct the DFA directly from the regex using derivatives. this derivative-based lazy DFA construction technique comes from the .NET NonBacktracking engine (2023).
back to our matching loop again, we can add one more detail - the next state may or may not exist yet, so we need to check for that and construct it on the fly if it doesn't:
state = 0
for character in input:
charKind = charClassTable[character]
+ if nextStateTable[state, charKind] = NONE: constructNextState(state, charKind)
state = nextStateTable[state, charKind]
if matchTable[state]: print "confirmed: a match {rel[state]} characters ago"
sometimes we compile a full DFA ahead of time as well - it's a configurable size threshold in RE#, but lazy construction with a 100-state threshold is the default and i'd recommend it for most use cases, since it gives you the best of both worlds - you can handle large regexes without worrying about blowup, but you also get very fast matching for the common case.
and like i said, the DFA can also be infinite, but it "blows up" at a rate of at most one state per character in the input, so it will terminate and likely not cause any real issues. the number of states is bounded by the maximum context distance that you need to keep track of for lookarounds, so using infinite context patterns like a(?=.*b) will never create more states than the length of the longest line in your input.
the last safety net is that we can also configure a hard limit on the number of states, and you will hit that limit with an exception before running into an infinite loop. another possible safety net is to just bound the context distance: a(?=.{0,100}b) and not consider context after 100 characters.
so why F#
RE# builds on top of .NET's regex infrastructure. the parser comes from the .NET runtime
with some modifications. the SIMD vectorization uses .NET's excellent SearchValues<T>.
the Teddy multi-string search algorithm was recently added to .NET 9, which boosted our results quite a bit. writing in F# means direct access to all of this with zero interop cost. not to mention RyuJIT has codegen comparable to native languages.
we also have a Rust implementation of the core engine, but it's there because we want a native library without dependencies and good UTF-8 support, not because it's necessarily faster. in fact, the F# version is currently faster than the Rust version - .NET has an effortless way to vectorize regexes with SearchValues<T>, and our implementation is able to detect and use these opportunities when most other engines can't. replicating what .NET gives you for free would take considerable effort, and i haven't done that in Rust yet - especially since many existing SIMD subroutines only work left to right, while .NET also provides right-to-left variants needed for our bidirectional matching.
the code doesn't look like idiomatic F#. the hot paths are full of mutable state, spans, and memory-pooled arrays. earlier versions even used raw pointers. F# is first and foremost a functional language, and bending it toward low-level systems programming took some effort. but it does support the constructs you need when performance matters, and the language really shines where it counts most for this project: expressing the algorithms themselves. the core data structure for regexes is a recursive discriminated union, which is a natural fit for F#'s algebraic data types:
type RegexNodeId = int32
[<Struct>]
type RegexNode<'tset> =
| Singleton of 'tset
| Or of nodes: RegexNodeId[]
| And of nodes: RegexNodeId[]
| Not of node: RegexNodeId
| Loop of node: RegexNodeId * low: int * up: int
| Concat of head: RegexNodeId * tail: RegexNodeId
| LookAround of node: RegexNodeId * lookBack: bool * ...
| Begin
| Endthe derivative function, the nullability check, the rewrite rules - they're all structural recursion over this type. F#'s pattern matching makes this natural to write and natural to read. and when you need raw performance in the hot loop, SRTP, inlining, and even raw embedded IL are right there.

semantics, what should a regex engine do when there are multiple possible matches?
this is a surprisingly controversial topic, and one that is often overlooked in academic research, and not well known in the industry.
what substrings does the regex (a|ab)+ match in the following input?
aababaababthink about it:
- the full string
aababaababis a valid match:a·ab·ab·a·ab·ab
a backtracking engine (meaning most of them) gives you 4 matches here:
aababaabab
RE# gives you 1 match - the entire string:
aababaabab
this isn't just an academic curiosity. flip the alternation order to (ab|a)+ and suddenly PCRE matches the entire string! the | operator in backtracking engines is ordered - it means "try left first", not union. the order of branches changes the result, which means | is not commutative. a|b and b|a can give different matches.
this breaks things that should obviously work. take the distributive law: (a|ab)(c|b) and (a|ab)c|(a|ab)b are logically the same pattern - you can verify this yourself by just expanding the terms. but in PCRE, the first matches ab in the input abc, while the second matches abc. two equivalent patterns, two different results.
and this is the core of why we care: extended operators do not make sense with an ordered OR. if | isn't commutative, then boolean algebra falls apart. A & B is supposed to equal B & A. ~~A is supposed to equal A. these identities rely on | being true union, not "try left first". so if you want & and ~ to work correctly, you need commutative semantics. this isn't a style choice, it's a mathematical necessity. and surprisingly also a reason for our amazing benchmark results - leftmost-longest lets you simplify your regexes without changing the matches, which i will elaborate on in another post, but for now just take my word for it that this is a huge deal for performance.
the standard that defines leftmost-longest is called POSIX, and despite the name suggesting it's specific to unix, it's really just the most natural interpretation: among all matches starting at the leftmost position, pick the longest one. this is what grep does, what awk does, and what RE# does.
how does RE# find the leftmost-longest match efficiently? remember the bidirectional scanning we mentioned earlier - run the DFA right to left to find all possible match starts, then run a reversed DFA left to right to find the ends. the leftmost start paired with the rightmost end (starting from that particular match) gives you leftmost-longest. two linear DFA scans, no backtracking, no ambiguity.
here's a subtle but important consequence: in RE#, rewriting your regex using boolean algebra is always safe. factor out common prefixes, distribute over union, apply de Morgan's laws - the matches won't change. your regex is a specification of a set of strings, and the engine faithfully finds the leftmost-longest element of that set in the input. no surprises from alternation order, no "well it depends on how PCRE explores this search tree". just set theory.
there's a ton of bugs in industrial applications that come from this kind of "it depends" behavior, and it's a nightmare for testing and maintenance. even LLMs get this wrong all the time because they've been trained for an eternity of people getting it wrong all the time - you wouldn't believe the types of human-hallucinated answers there are out there on stack overflow. perhaps one last thing to say here is that leftmost-longest can express every single pattern that leftmost-greedy can. it is a more general form. want to return the same results from (a|ab)+ as PCRE? just rewrite it as (a)+ - that's what it is. the very fact that there is a difference at all means that there was a bug in the PCRE pattern, ab is an unreachable branch.
finding all matches, the llmatch algorithm implementation
i want it to be understood that "finding the (1) match" with our llmatch algorithm is a little silly - why would we start matching backwards if we want the first match. it makes absolutely no sense. you must be out of your mind to start reading a terabyte log file from the end to find the match on the first line.
but our algorithm is not for "the (1)" match, it's designed to mark-and-sweep through all matches in the input, and looking back, the paper does not highlight the importance of this as much as it should. without pointing this out, we would have the slowest first match algorithm in the world.
it was initially counterintuitive and hard for me to accept as well, but let me really illustrate how it works. in the paper, we describe an example where we want to find author names using context assertions, described roughly as follows:
- located between
{and} - preceded by the word "author" on the same line
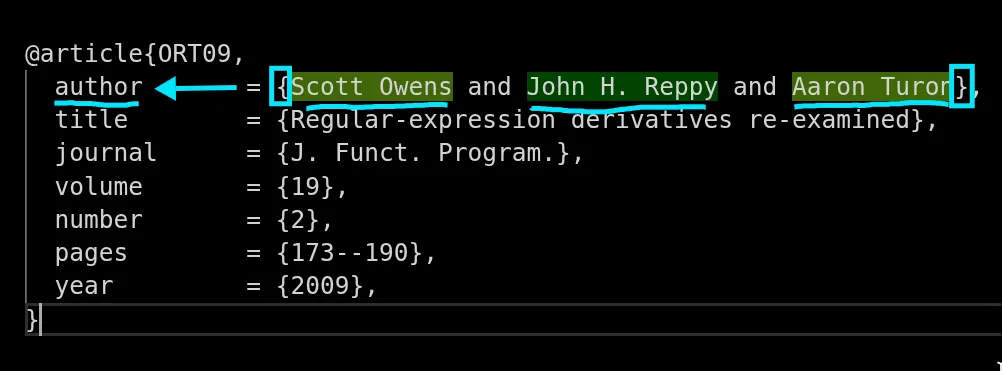
and the magic here is that we can do this with zero back-and-forth movement. we find the matches with two linear scans, one right to left to mark exactly where the matches start, and one left to right to eliminate overlap. right to left sweep marks all matches in a single pass. it's completely deterministic, every possible future has been accounted for, and we just let the automaton do its thing.
start from the end of the text (below), and as you move left, you will encounter a lot of "possible matches" that are waiting for confirmation. all the heavy computation has already been done in the states of the automaton, which are reused for subsequent characters, so after initial wind-up time, you will not create any new states, just reusing the same ones over and over again, and marking the positions of matches as you go.
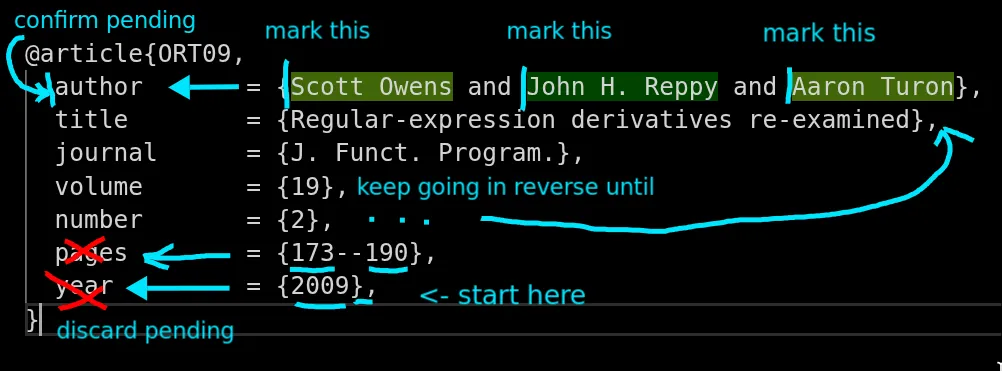
this is a very powerful technique, and it is the main reason why we are so fast on the benchmarks, because by the time we confirm a match, both the lookbehind and lookahead have already been matched - we report matches retroactively once all the context is known, instead of trying to look into the future or backtracking to the past or keeping track of NFA states. this is a very different way of thinking about regex matching, and it took me a while to wrap my head around it, but once you see it in action, i hope you appreciate how elegant and efficient it is.
and of course for IsMatch there is no difference in which direction you go, you can just stop at the first match and return true. in fact lookarounds aren't necessary for IsMatch at all, they are indistinguishable from concatenation. a(?=b) is just ab for the purposes of IsMatch and a(?=.*b)(?=.*c) is just a(.*b_*&.*c_*) - the lookarounds only come into play when you want to know the position of the match, and what is around it. if you happen to use lookarounds in an IsMatch pattern today, consider RE# intersections a faster drop-in replacement with identical semantics.
what about the other linear lookaround approaches?
two other recent works tackle linear-time lookaround matching: Mamouras et al. (POPL 2024) and linearJS by Barriere et al. (PLDI 2024). both are interesting contributions that approach the problem very differently from us, and both support arbitrary lookarounds with nesting, which is a nice feature to have.
i haven't found an implementation of the first one (update: a Haskell implementation by a different author exists). the second targets javascript and should be available in node/chromium at some point. running /(a+)*b$/.test("aaaaaaaaaaaaaaaaaaaaaaaaaaaaaba") in my browser console still makes the fans spin for 10 seconds, so i'm fairly sure it hasn't shipped yet. without implementations and benchmarks to compare against, i can only comment on the theoretical differences.
both of these approaches use NFAs under the hood, which means O(m * n) matching. our approach is fundamentally different: we encode lookaround information directly in the automaton via derivatives, which gives us O(n) matching with a small constant. the trade-off is that we restrict lookarounds to a normalized form (?<=R1)R2(?=R3) where R1/R2/R3 themselves don't contain lookarounds. the oracle-based approaches support more general nesting, but pay for it in the matching loop. one open question i have is how they handle memory for the oracle table - if you read a gigabyte of text, do you keep a gigabyte-sized table in memory for each lookaround in the pattern?
i don't think one approach is strictly better than the other. if you need arbitrarily nested lookarounds, the oracle-based approaches are the way to go. if you need high performance and are ok with a more restricted form, ours should work well.
conclusion
RE# started as a research project to combine multiple things - first we wanted to bring boolean operators back from the 1964 paper where they originated, then we wanted to extend the .NET NonBacktracking engine, which was, the way i see it, being held back by backwards compatibility (i.e., a safe drop-in replacement for the PCRE existing engine, which meant that it had to support the same features and semantics). we wanted to break free from those limitations and see how far we can push the new engine without worrying about compatibility.
the key ingredients were Brzozowski derivatives, minterm compression, lazy DFA construction without NFAs, and encoding context awareness directly into states. most of these ideas aren't individually new - the magic is in the matching algorithm that puts them together in a way that is correct, fast and practical.
there's a lot of other things that i haven't even touched on here, like the optimizations we compute ahead of time for specific patterns, how we detect match prefixes, the differences of UTF-16 and UTF-8 matching and unicode, what is the backwards compatibility story, how we can skip through text that others cannot. i haven't even mentioned Hyperscan, which is a very interesting engine that is actually based on a completely different 1961 paper, and so on, there's a lot to share so perhaps i will look into these topics in the future.
if there's one thing i hope you take away from this, it's that intersection and complement are genuinely useful operators that have been missing from regex engines for far too long. being able to describe what you want as a combination of properties, rather than cramming everything into one monolithic pattern, is a much more natural way to think about matching. and now you can do it with linear-time guarantees.
the engine is open source and available as a nuget package. try it out, play with the web app, and if you find bugs or have ideas, let us know. the paper is available at POPL 2025 for those who want the full formal treatment.