what 262,715 regex questions on stack overflow haven't answered (part 2)
the html question, the regex that passes and fails on the same input, and other things you may find surprising
part one was mostly about extended regex operators: complement and intersection. this is a shorter post than the first one. i'm working day and night on a dissertation right now, so instead of a longer essay it's about the famous HTML question and a rant about fallback logic and a few more surprises.
the most famous answer on stack overflow
Q1732348 (4.1M views): "RegEx match open tags except XHTML self-contained tags." the asker wants a regex that matches <b> but not <br />.
I need to match all of these opening tags:
<p>,<a href="foo">. But not self-closing tags:<br />,<hr class="foo" />. I came up with<([a-z]+) *[^/]*?>. Do I have that right? And more importantly, what do you think?
the accepted answer:
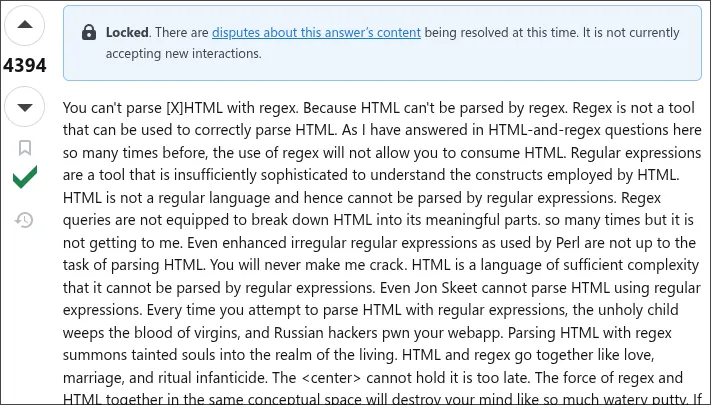
the classic academic answer is that it is impossible. but there's more to this: to see how and why, let's consult sisyphus.

from far enough away, HTML looks tiny: open angle, close angle, some element names, attributes between them. on snippets like <p> or <a href="foo">, regex actually works. but let's be more ambitious and set our sights on real spec-compliant HTML.
bringing in a little formal language theory to see why, the idea is that you can rank languages by how much computational power it takes to parse them. this has consequences for speed and memory usage, implementation complexity, and also how easily you can analyze them for eg. security holes. below is a rough sketch of what it looks like in the real world.

yes, the summit. if HTML was a sane data format, it would sit one tier up from regex, with JSON and XML. but that would be much less interesting. the WHATWG parsing spec, §13.2, defines parser behavior for html documents "whether they are syntactically correct or not," with explicit parse-error recovery rules: implicit tag closing, foster parenting, the adoption agency algorithm, insertion modes that switch based on what's already been parsed. no grammar describes this and the spec is the algorithm, that's why HTML lives at the top.
this puts sisyphus in an even more soul-crushing position. you could write a regex thousands of lines long, but it wouldn't even get you outside the regular band. the HTML peak is out of reach. but just as HTML in the real world is not as it seems, neither is industrial regex. engines like PCRE, .NET, and Perl are all vastly more powerful than the textbook definition of a regular expression. somewhere along the way the pattern language grew a programming language inside it.
which means the hero of our little story was never sisyphus.

when the academic problem statement leaves us rolling a ball up a hill for eternity, industrial regex gives us wings: backreferences, lookarounds, balancing groups, recursion.
backreferences alone already push us past context-free: (.+)\1 matches verbatim copies like abcabc, which no CFG can recognize. then with .NET's balancing groups we have unbounded stateful memory, repetition and conditional branching. together that's turing-complete. we have the power to reach the HTML summit. it is possible to write a "regex" that at the very least recognizes HTML and extracts substrings from it.

but the closer we fly to the HTML summit, the hotter the sun of algorithmic complexity gets: as the power increases so does the cost. matching with backreferences is already NP-hard, and recursion and balancing groups only make it worse. cover enough of the spec and somewhere in that pattern there's an input that takes exponential or even infinite time to reject.
so we land exactly where the stackoverflow answer landed. a true regular expression can't match HTML, and even with a fancy turing-complete engine you shouldn't.
but HTML defeats much more than just regex
standardizing a language that accepts everything has a cost in the form of implementation complexity. cross-site scripting (XSS) happens when an attacker gets their HTML or JS into a page another user loads. the spec's tolerance for malformed input hands attackers a lot of bypass tricks: any shape the parser accepts and the sanitizer didn't anticipate slips past the filter. think of it as a security door where you can insert some well crafted gibberish as credentials, and the door goes "well this makes no sense" and defaults to letting you in.
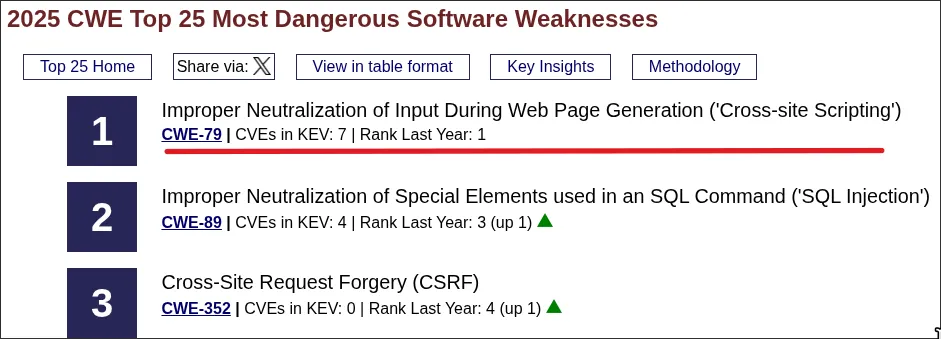
almost every popular web platform ships HTML sanitization, and almost all of them have shipped a bypass at some point. the dedicated sanitizer libraries aren't bulletproof either. while writing this i came across one that was fixed days ago: Chrome shipped a new HTML element and DOMPurify hadn't caught up to it yet. given a living standard like this, it's no surprise that MITRE and CISA put XSS at #1 on the CWE Top 25, in both 2024 and 2025.
and this is the next point i wanted to get to. HTML is full of fallback behavior that's hard to reason about, far more than regex could describe.
fallbacks
the broader pattern here is something i've been bitten by a lot. a lot of software is designed to hide errors at any cost. malformed input gets a guess, invalid syntax gets a fallback, critical bugs get swept under the carpet. in other words playing with broken glass is preferred over "mom walking in and yelling", which ruins the fun.
web technology in general is an excellent example of this, you may be aware that JavaScript, the language, has a lot of quirks. but let's look at JS regex in the browser. when its parser can't read a pattern the obvious way, it tries another reading until one succeeds. you get a match and a value, with no error to signal that the meaning differs from what you wrote. a few examples that may catch you off guard.
/a\1/.test("a\x01") // true; \1 is a control character
/(a)\1/.test("aa") // true; \1 is a backreference
/(a)\8/.test("a8") // true; \8 is literal "8"
/a{1,1}/.test("a") // true; "a", unsurprising
/a{1,1.}/.test("a{1,1x}") // true; literal "a{1,1" + any + "}"
/\z/.test("z") // true; literal "z", "end of input" in many others/[a-\w]/.test("-") // true; a-\w invalid range, "-" is literal
/[a-\p{L}]/.test("-") // false; double whammy: \p turns to "p" then into 'a-p' range
/a{2,1}/.test("a") // surprise! this one throws an errorthe engine silently rewrites your regex when it can't parse it as written. this shows up in answers too. Q30225552: asker pastes /([.\p{L}])/g, accepted answer (49 score) declares "JavaScript does not support \p{L}". it was actually parsed as [.pL{}], with \ thrown away. Q3617797: top answer gives \p{L} without mentioning it parses as the literal "p{L}" unless you set the /u flag.
the /u flag alone would fix most of these. people mainly use it for unicode support, but it does something else too: it makes the parser stricter, so these broken patterns throw instead of getting silently rewritten. i don't think that second part is well known, it was a big surprise to me. but the flag itself is used on a small fraction of patterns, so in practice these silent fallbacks fly under the radar.
idempotency
you'd expect the same pattern and the same input to give the same result every time. but this is not always true.
Q1520800. the asker's summary: "the result should be [true, true]". .test() looks like a predicate but with /g it's a stateful iterator that alternates between true and false on the same input.
const re = /^a$/g;
for (let i = 0; i < 6; i++) {
console.log(re.test("a"));
}
// true, false, true, false, true, falsea /g regex stores lastIndex, where the next search begins. after a match it advances past the match; the next test() starts from there, finds nothing, resets to 0, and succeeds again. the same regex alternates pass/fail on the same input. it breaks array methods too:
const re = /^\d+$/g;
["1", "abc", "2", "3"].filter(s => re.test(s));
// expected: ["1", "2", "3"]
// actual: ["1", "2"]String.prototype.matchAll (ES2020) gives you a fresh state and doesn't have this problem.
i suspected this one had generated some frustration, so i went looking and it had. here is the top comment (133 votes):
This is like Hitchhiker's Guide to the Galaxy API design here. "That pitfall that you fell in has been perfectly documented in the spec for several years, if you had only bothered to check"
and on the question itself, summing up the whole genre:
Welcome to one of the many traps of RegExp in JavaScript. It has one of the worst interfaces to regex processing I've ever met, full of weird side-effects and obscure caveats.
reading these leaves me in a strange position trying to tell you that regex isn't complicated or difficult to use, because if you look at it like that, it absolutely is. there is a big gap between how much pain is necessary, like learning the meaning of ., | or *, and how much is artificially inflated by arcane knowledge of specific regex APIs, "leftmost-greedy" matching and "whoops you made a typo, this now takes 1 year to process". this applies to other languages as well, not just JS.
a quantified capture only keeps the last iteration
this one is better known. it is not immediately obvious what a capturing group should do if it matches multiple times.
Q37003623: asker writes ^(?:([A-Z]+),?)+$ for "HELLO,THERE,WORLD" and reports "my regex is actually capturing only the last one, which is 'WORLD'".
when you put a capturing group under +, *, or {n,m}, every iteration overwrites the group's value with the next one and only the final iteration survives.
"abcabc".match(/(abc)+/)
// ["abcabc", "abc"] full match spans both, group 1 only keeps the last
"123456".match(/(\d{2})+/)
// ["123456", "56"] three pairs matched, one survives in the capturethe full match contains every iteration, but the captures get used to advance the engine then thrown away. .NET is an exception, exposing a CaptureCollection per group:
Regex.Match("123456", @"(\d{2})+").Groups[1].Captures
// ["12", "34", "56"]since it is common unintended behavior, regex101.com (below) flags this as a warning automatically.
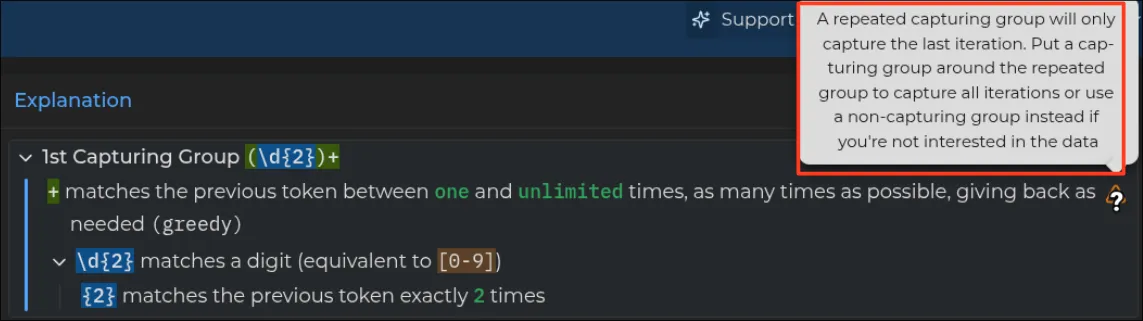
i cannot think of a case where you'd actually want only the last group, so it could just be a parse error. but that would reject extremely common patterns like (ab)+ where you never cared about the capture in the first place.
\b is not a word start / end by itself
Q1324676: asker writes \b-?\d+\b to match signed integers like -12, but it doesn't match the -.
the catch is that \b doesn't mean "where a word starts." it marks the spot where a word character meets a non-word character. a digit like 1 counts as a word character; a dash doesn't. so in -12 the boundary sits between the - and the 1, not before the -, and the match starts at the 1 with the minus sign left behind.
same trap at Q1751301, matching S.P.E.C.T.R.E. with \b...\b. the name ends in a ., which isn't a word character, so there's no boundary after it for the closing \b to land on, and the match fails.
\b and \B only work as expected when they're next to an unambiguous word or non-word character, combining them with character sets where you have both word or non-word characters like [.a]\b may open you to a lot of surprises. or if you strictly mean "next char is a whitespace or dash or the end", it's safer to use something explicit like (?=[\s-]|\z), although much less readable than \b for "boundary".
one more difference: \w isn't quite the opposite of \W at a boundary. the Unicode spec says a correct \b should treat two invisible characters, "zero width joiner" and "zero width non-joiner", as part of a word even though neither counts as \w. so the boundary rule and the simple \w/\W split don't always agree. digging through real world specs is always surprising. even "where does a word end" is not always as it seems.
alternation has the lowest precedence
this last one is well known, but common enough to belong here anyway.
^cat|dog$ is not the same as ^(cat|dog)$. the | has the lowest precedence of anything in a regex, lower than concatenation, repetition, and the anchors. so ^cat|dog$ actually means (^cat)|(dog$): "starts with cat" or "ends with dog", not "is exactly cat or dog."
/^cat|dog$/.test("hotdog") // true; ends with "dog"
/^cat|dog$/.test("catfish") // true; starts with "cat"
/^cat|dog$/.test("fishcat") // falsethe solution is to group the alternatives: ^(cat|dog)$. Q51959733 is an example of this. the asker wants /^a*|b*$/ to mean "only a's and b's", then is surprised that it matches "c":
/^a*|b*$/.test("c") // trueit parses as (^a*)|(b*$), and ^a* happily matches zero a's at the start of any string, so everything passes. the bug hides whenever the wrong split happens to agree with the intended one. /^error|warning|info:/ parses as (^error)|(warning)|(info:), so the middle warning is unanchored and matches anywhere in a string, regardless of prefix. log filters and routers written this way quietly over-match.
part one was about operators most mainstream engines don't have. this part was about what they do have, and where it may not be what you expected.
on a closing note: thanks to the help of a few contributors, a lot of outstanding bugs in RE# have been fixed lately. if you want to help out, give it a try and let me know if you run into anything before a proper 1.0 release.