gzip decompression in 250 lines of rust
i wanted to have a deeper understanding of how compression actually works, so i wrote a gzip decompressor from scratch. the result is about 250 lines of rust that can decompress gzip from a file or stdin.

why bother?
gzip is everywhere. it compresses your web traffic, your log files, your documentation / man pages, it is the format commoncrawl stores 300 billion pages and hundreds of terabytes of web archives in. it sits invisibly between disks, networks, and CPUs, quietly shaving off bytes at planetary scale, so boringly reliable that the browser won't bother telling you it’s there at all. it's a fundamental tool in the software ecosystem. so let's read it, the first thing to do is clone zlib and start reading through the source code, right? well lets first see how long it is:
/mnt/g/repos/zlib
❯ fd -e c -0 | xargs -0 cat | wc -l
25569twenty five thousand lines of pure C not counting CMake files. (and whenever working with C always keep in mind that C stands for CVE).
ok maybe we can find a smaller implementation. perhaps zlib-rs is more digestible:
/mnt/g/repos/zlib-rs
❯ fd -e rs -0 | xargs -0 cat | wc -l
36003thirty six thousand lines of rust. that's a bit more than i wanted to read through.. actually there is a smaller implementation called miniz which is only 1261 lines of C if you combine the header and source:
/mnt/g/repos/miniz
❯ cat miniz.c miniz.h | wc -l
1261the problem is just looking at miniz is not going to give you a good understanding of how gzip works. it's a single file, but it's still 1200 lines of code with a lot of optimizations and c preprocessor string substitutions stitched together. i wanted something even simpler, something that just implements the core ideas without worrying about checksums or features that aren't used in practice.
the gzip wrapper
gzip itself is just a thin wrapper around the DEFLATE algorithm (the same one used by .zip files and .png files).
the file starts with a magic number (0x1F 0x8B), followed by some flags and metadata, and then the compressed data. parsing it is straightforward:

assert!(buf[0] == 0x1F && buf[1] == 0x8B, "not a gzip file");
let mut offset = 10; // skip the fixed header
if buf[3] == 8 { // FNAME flag - filename is present, find null byte to skip it
offset += buf[10..].iter().position(|&b| b == 0).unwrap() + 1;
}
// we don't care about other flags, so we can ignore themthe only flag we care about is FNAME, which contains the name of
the file that was compressed. we skip it by looking for the next null byte as is standard in C.
the real work happens in the inflate function that processes the DEFLATE stream. there's many other features in gzip, such as the operating system that was used to create the file, or the original file size, but we don't
need any of them to decompress the data, so we can ignore them.
DEFLATE blocks
DEFLATE data is organized into blocks. each block starts with a bit indicating whether it's the last block, followed by a 2-bit type:
- type 0: stored (uncompressed) data
- type 1: compressed with fixed huffman codes
- type 2: compressed with dynamic huffman codes
loop {
let last = s.bits(1);
match s.bits(2) {
0 => stored(&mut s, &mut out),
1 => fixed(&mut s, &mut out),
2 => dynamic(&mut s, &mut out),
_ => panic!("invalid block type"),
}
if last != 0 {
break;
}
}stored blocks are trivial - just copy the bytes directly. the interesting stuff happens in fixed and dynamic blocks.
reading bits
before we get to huffman codes, we need a way to read individual bits from the input stream. DEFLATE packs bits from least significant bit to most significant bit within each byte:

the code is a bit fiddly, and bit manipulation is never pretty to look at, but the idea is that we read bits in reverse order within each byte. when we need more bits than we have, we read another byte and shift it into place. the bits function handles this logic:
// the graph is much simpler than the code, but here it is for reference
fn bits(&mut self, need: i32) -> i32 {
let mut val = self.bit_buffer;
while self.bit_count < need {
val |= (self.nextbyte() as i32) << self.bit_count;
self.bit_count += 8;
}
self.bit_buffer = val >> need;
self.bit_count -= need;
val & ((1i32 << need) - 1)
}we maintain a buffer of bits we've read but not yet consumed. when we need more bits than we have, we read another byte and shift it into place.
huffman coding
the insight of huffman coding is that common symbols should use fewer bits. if 'e' appears 1000 times and 'z' appears twice, it's wasteful to use 8 bits for both. huffman assigns shorter codes to frequent symbols and longer codes to rare ones.

DEFLATE uses canonical huffman codes, which means the codes are determined entirely by the bit lengths assigned to each symbol. given the lengths, we can reconstruct the actual codes:
fn construct(h: &mut Huffman, length: &[u16], n: usize) -> i32 {
// count how many codes of each length
h.count[..=MAXBITS].fill(0);
for i in 0..n {
h.count[length[i] as usize] += 1;
}
// compute starting code for each length
let mut offs = [0i16; MAXBITS + 1];
for len in 1..MAXBITS {
offs[len + 1] = offs[len] + h.count[len];
}
// assign symbols to codes
for sym in 0..n {
if length[sym] != 0 {
h.symbol[offs[length[sym] as usize] as usize] = sym as i16;
offs[length[sym] as usize] += 1;
}
}
// ...
}decoding is done bit by bit. we read a bit, and check if we have a valid code. if not, we read another bit and try again - in practice most optimized implementations use a lookup table, but the bit-by-bit approach works just fine for our implementation:
fn decode(s: &mut State, h: &Huffman) -> i32 {
let (mut len, mut code, mut first, mut index) = (1, 0, 0, 0);
loop {
code |= bitbuf & 1;
bitbuf >>= 1;
let count = h.count[next_idx] as i32;
if code < first + count {
return h.symbol[(index + code - first) as usize] as i32;
}
index += count;
first = (first + count) << 1;
code <<= 1;
len += 1;
// ...
}
}fixed vs dynamic codes
fixed huffman blocks use a predefined set of code lengths. literals 0-143 get 8 bits, 144-255 get 9 bits, and so on. this is simple but not optimal for all data.
dynamic blocks include their own huffman tables at the start of the block. this adds overhead, but allows the compressor to tailor the codes to the actual data. most real-world gzip files use dynamic blocks.
the meta-twist is that the code lengths themselves are huffman encoded. so we first decode a huffman table to decode the huffman table that we'll use to decode the actual data.

fn dynamic(s: &mut State, out: &mut Vec<u8>) {
let (nlen, ndist, ncode) = (
s.bits(5) as usize + 257,
s.bits(5) as usize + 1,
s.bits(4) as usize + 4,
);
// read code length code lengths (yes, really)
let mut lengths = [0u16; MAXLCODES + MAXDCODES];
for i in 0..ncode {
lengths[ORDER[i]] = s.bits(3) as u16;
}
// build huffman table for code lengths
construct(&mut lc, &lengths, 19);
// use it to decode the actual code lengths
// ...
}LZ77: back-references
huffman coding alone can't achieve great compression. the real power comes from LZ77, which replaces repeated sequences with back-references.

when the decoder sees a literal symbol (0-255), it outputs that byte directly. but symbols 257-285 are special - they indicate a length/distance pair. "copy 9 bytes from 50 bytes ago" is much shorter than repeating those 9 bytes.
if sym < 256 {
s.output(out, sym as u8);
} else if sym > 256 {
let idx = (sym - 257) as usize;
let len = LENS[idx] as i32 + s.bits(LEXT[idx] as i32);
let dsym = decode(s, dc) as usize;
let dist = DISTS[dsym] as u32 + s.bits(DEXT[dsym] as i32) as u32;
for _ in 0..len {
let c = s.window[s.next.wrapping_sub(dist as usize) & (MAXDIST - 1)];
s.output(out, c);
}
}the length and distance codes have extra bits for fine-grained values. symbol 265 means "length 11-12" and the next bit tells you which. this keeps the huffman alphabet small while still supporting lengths up to 258 and distances up to 32768.
we maintain a 32KB sliding window of recently output bytes for back-references. the & (MAXDIST - 1) trick works because MAXDIST is a power of two - it's a fast way to wrap around the circular sliding window.
forward references
actually lz77 back-references can refer to data that hasn't been output yet. a good example is the string "aaaaaaaaa", which can be represented as two lz77 blocks: first block is "a" (literal), second block is "copy 8 bytes from 1 byte ago". when we decode the second block, we haven't output those 8 bytes yet, but we can still copy them because we are producing them as we go. this lets us output repeated sequences without needing to store the entire uncompressed data in memory first. (although not too much since the maximum length of a back-reference is only 258 bytes by spec).

putting it together
the full decompressor is about 250 lines. here's how you'd use it:
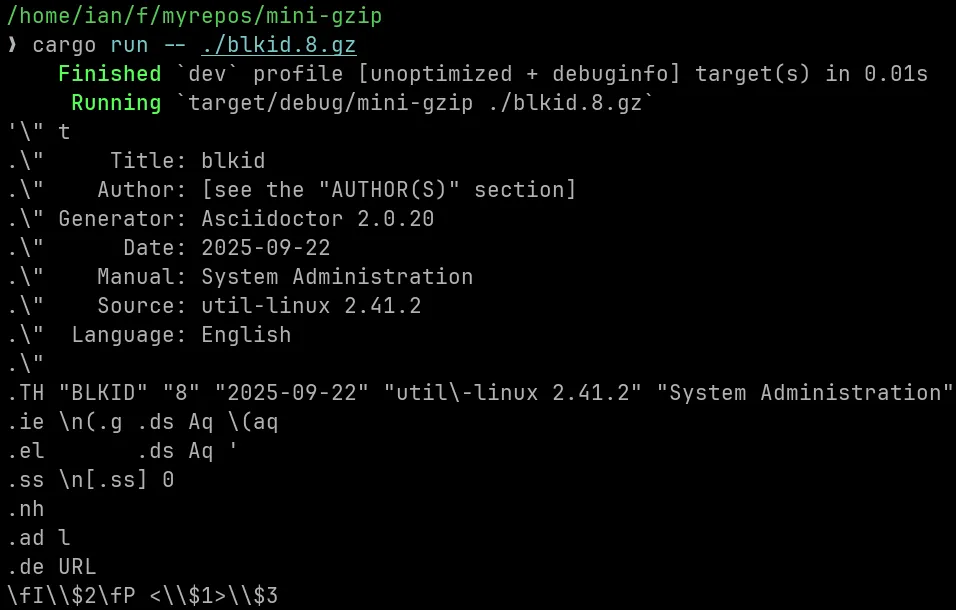
or we can even visit google.com with curl, and decompress the response ourselves:
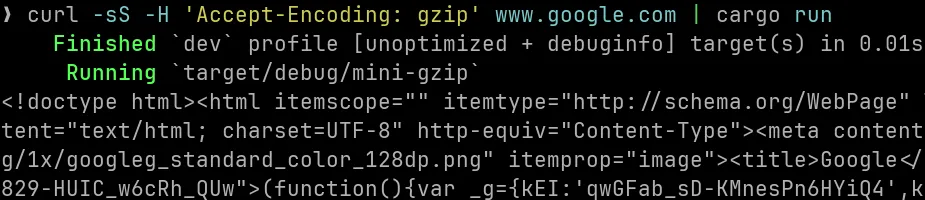
what i learned
gzip compression is layered - gzip wraps around huffman coded input, the huffman coded input wraps around lz77 back-references, and the back-references wrap around the actual bytes. you can do each step separately, but in practice implementations do them all in one pass.

getting to the first working implementation is the hard part - once you have something that can read a gzip file and output something that's not complete gibberish, you can iterate on it and improve it. starting from thousands of lines of optimized code is a lot more intimidating than starting from a simple implementation that just works.
the code handles all valid gzip files, though i wouldn't place it in production just yet - there's no CRC checking, and it panics on invalid input. but it works.
source code is available on github